![❤ Dataflows for Power Apps ❤: “The column ‘[Column_name]’ of the table wasn’t found.” error while loading multiple tables](https://msolenacrm.blog/wp-content/uploads/2021/01/notsofast.png.png?w=1024)
There is an option to load data to multiple table in one go in Dataflows. These tables can be related. Dataflow engine calculates the dependencies and determines the correct order for loading. It’s a very cool functionality, however, you have to be aware of some potential issues as well as available workarounds.
Problem: I am trying to load bills and meter data in to Dataverse tables. The Meter table’s linked to the Bill table. In my datasets, I load data from two CSV files. I’ve got a common Account ID column which is a unique key for the load. However, the actual alternate keys are Name (Bill) and Name (Meter).
Load Attempt 1:
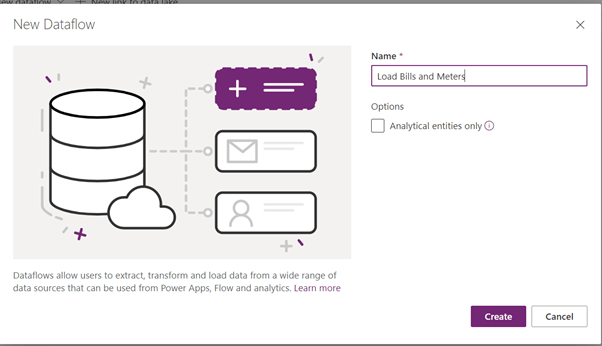
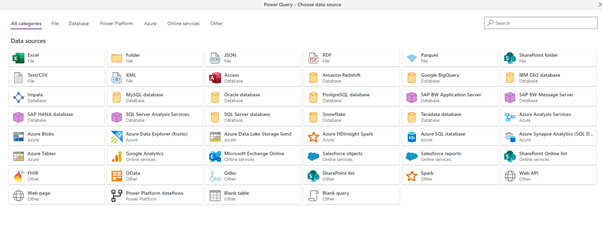
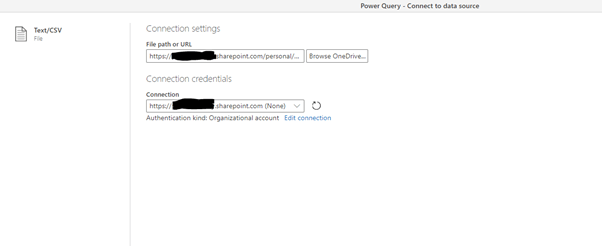
Let’s load data from the Bills CSV file.
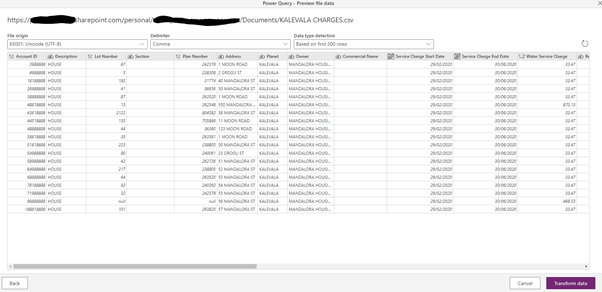

Let’s add the unique Name column.
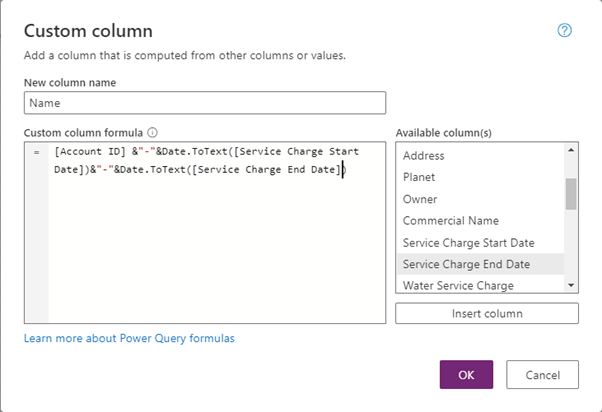
Now let’s add another query, for Meter Data CSV file.


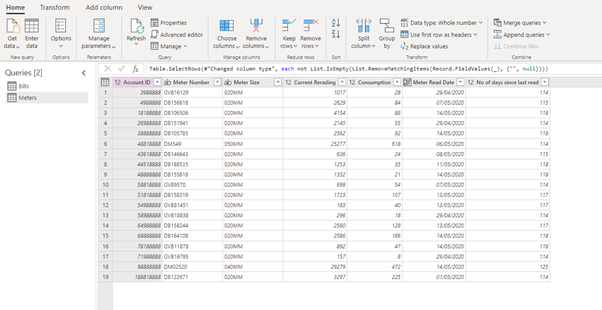
To link two datasets, let’s merge tables on Account ID.

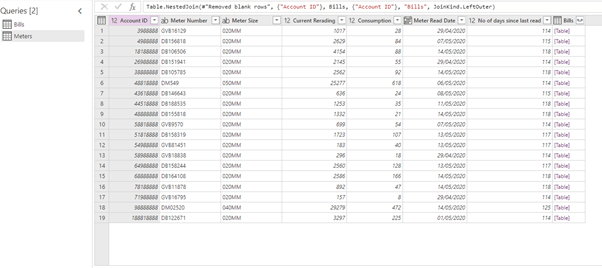
Now we’ve got the link between Bills and Meters.

Let’s add the uniques Meter Name column.

Let’s continue to the mappings for Bills…
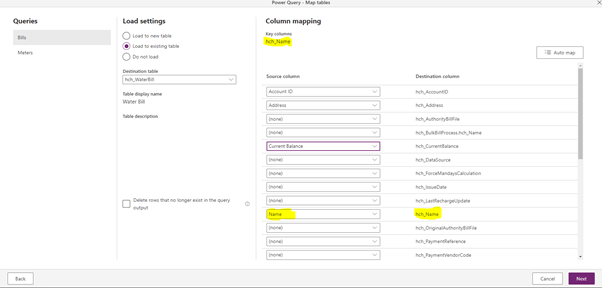
And for Meters.

Always make sure you mapped Names. or whatever your alternate key is.
We also map the reference from Bill to Meter.


Not so fast! The dataflow is failing with the tragically “informative error:
There was a problem refreshing the dataflow, the dataflow definition contained errors. Please fix the problem and try again. Additional information: Unexpected exception, Message: Expression.Error: The column 'XXXX ID' of the table wasn't found.
Whatever. Mama, I think I’ve just broke the engine…
I don’t know but (after hours of thinking I remembered I fixed it before) I tried loading both tables separately and it worked. So it’s something about the reference column. I believe it got lost in Merge trying to figure out dependencies.
Let’s save it and ourselves from the headache. Let’s split the calculation of the reference column and load to keep loading tables “independent”. This is the idea.
Let’s duplicate the parent, Bills, query.
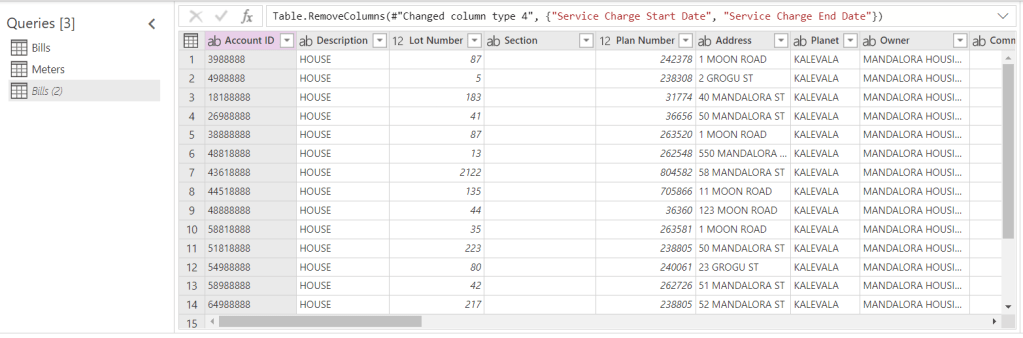
The Merge to get the reference column, we perform on the duplicated set Bills(2). We aren’t going to load it though.

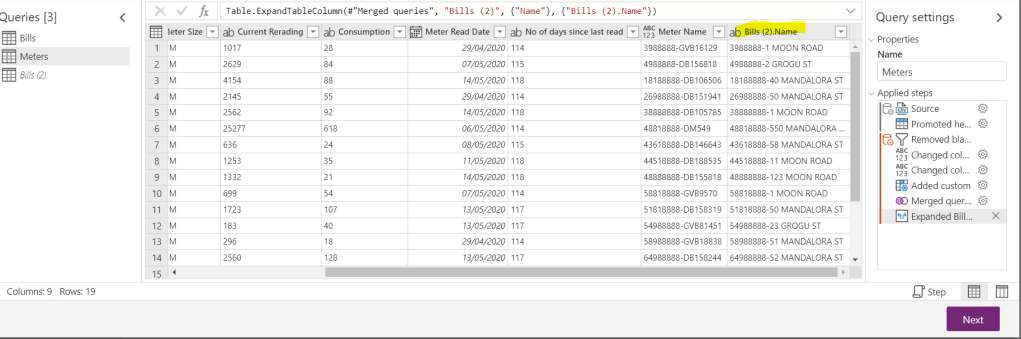
We’ve got our reference to Bills(2). But datasets Bills and Meters aren’t linked.

This time dataflow didn’t fail and data has been successfully loaded to Dataverse.
Bills:

Meters:
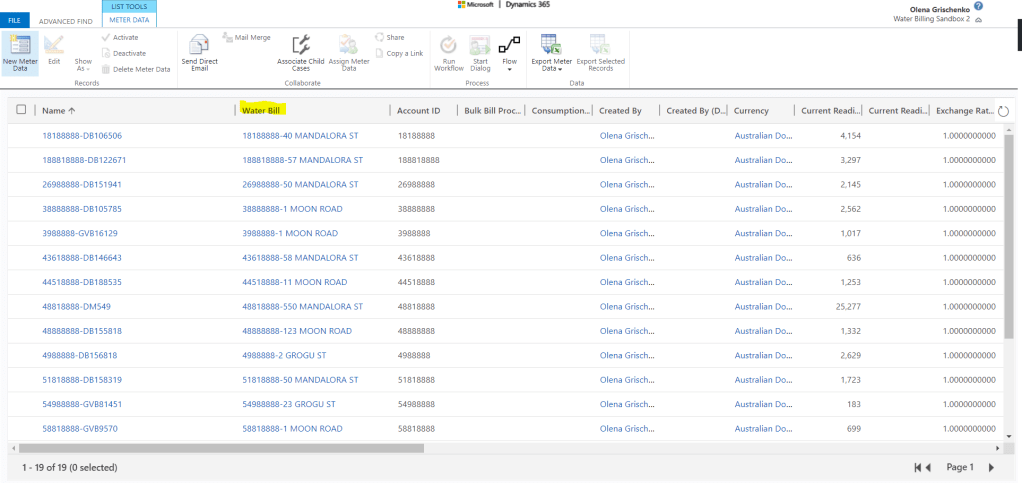
With the link to Bills.
Easy! 🤣🤣🤣

Leave a comment